Introduction to system scalability and reliability

Software Engineer | Mentor | Cats | Food | Loves to learn
Scalability and reliability are measures of how well your application can be served to end-users. If you have a system that can serve millions of users without noticeable downtime, then we can say the system is highly scalable and reliable.
When you're working with a product that has a large user base, a lot of things change. Google has to process at least 100K requests per second. Without a robust scalable architecture, it would have been absolutely impossible. Scalability and reliability are probably the major factors for which we need Software Engineers in the first place.
In this article, we will go through a conceptual overview of software scalability and reliability. To understand this article, you have to know the basics of web development and cloud. It's an engineer's job to make the product scalable and robust. But please note, these topics are very diverse and large books can be written on these things. How the whole system is laid out is called the architecture of the system, which addresses scalability/performance and reliability. Besides regular Software Engineers, companies will have separate Staff Engineers, Software Architects or Site Reliability Engineers who will solve architectural problems from a much higher level.
The topic where scalability and software architecture is discussed is known as System Design. It is a very different skill compared to your general problem solving or coding skills. You might think that your job performance will be evaluated depending on how much good code you write and how good a problem solver you are. It's true, but only for the first 2-3 years. For senior roles, you will be judged based on your system architectural skills. Generally, a company expects that you will contribute at an architectural level when you have around 2-3 years of job experience. So, if you really want to climb the success ladder, you have to have a good grasp of such topics.
Here, I will cover very basics of scalability and reliability. For the sake of understanding, we will think of a fictional project and see how it scales depending on the user base.
Let's say you have created a social platform named Circle (we will just assume this name for future references), which is very similar to Facebook. This is a hobby project and you have given it to some of your friends to test it. So, your friends like Circle and they start using it from time to time.
Case 1: Very small user base
Let's say Circle is doing well among your friends and currently you have the following metrics:
| Total Users | Concurrent Users | Requests/second | Latency |
| 500 | 100 | 70-80 | 1-2 sec |
For such a scenario, a 1GB single-core server worth 5$ and a managed database should be enough. How many loads your server can handle cannot be determined with any theories, because there aren't any exact theories or calculations. You have to implement monitoring and logging to know if you need to use more than one server.
But for the sake of this example, let's say your 5$ single server is handling the load pretty good with an acceptable amount of latency. Latency is the time required to complete a request. Whereas concurrent users are the number of users that are active in your website simultaneously at a time instant. You have the following simple architecture.
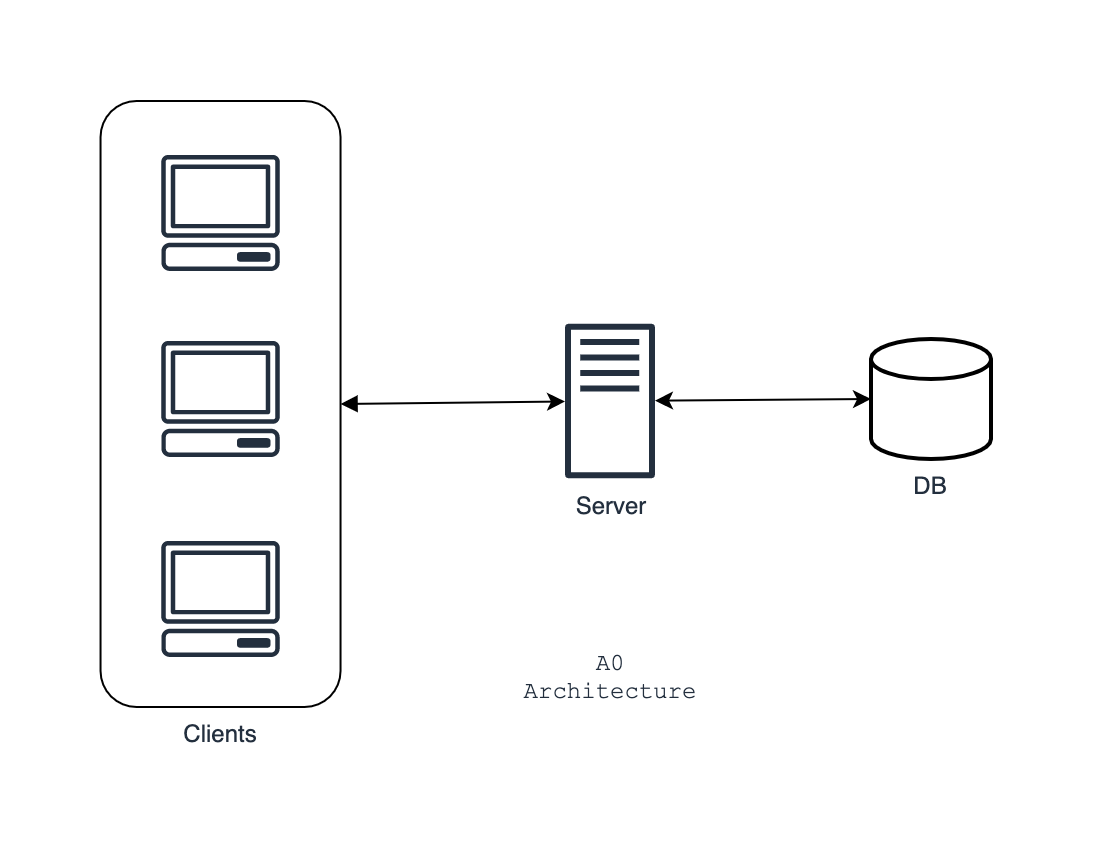
For future references, let's name this architecture A0.
Case 2: Small user base
More popularity, more users. With your current A0 architecture, you have the following metrics
| Total Users | Concurrent Users | Requests/second | Latency |
| 5000 | 2000 | 700-800 | 5-6 sec |
You might have already understood that latency is the metric that we're concerned about because that gives a clear idea of how the website is performing. So, things are not going well. The latency is not acceptable. It's a slow website now. A slow website is as good as a dead website. Also, you're seeing that due to excess load your single server is crashing sometimes. You have to improve the latency. If you can reduce server load, latency will improve as a side effect (and vice-versa).
So, you add another server to handle more load. You add a load balancer at the front. This will distribute the load equally between the two servers using round-robin technique. The architecture is as follows.
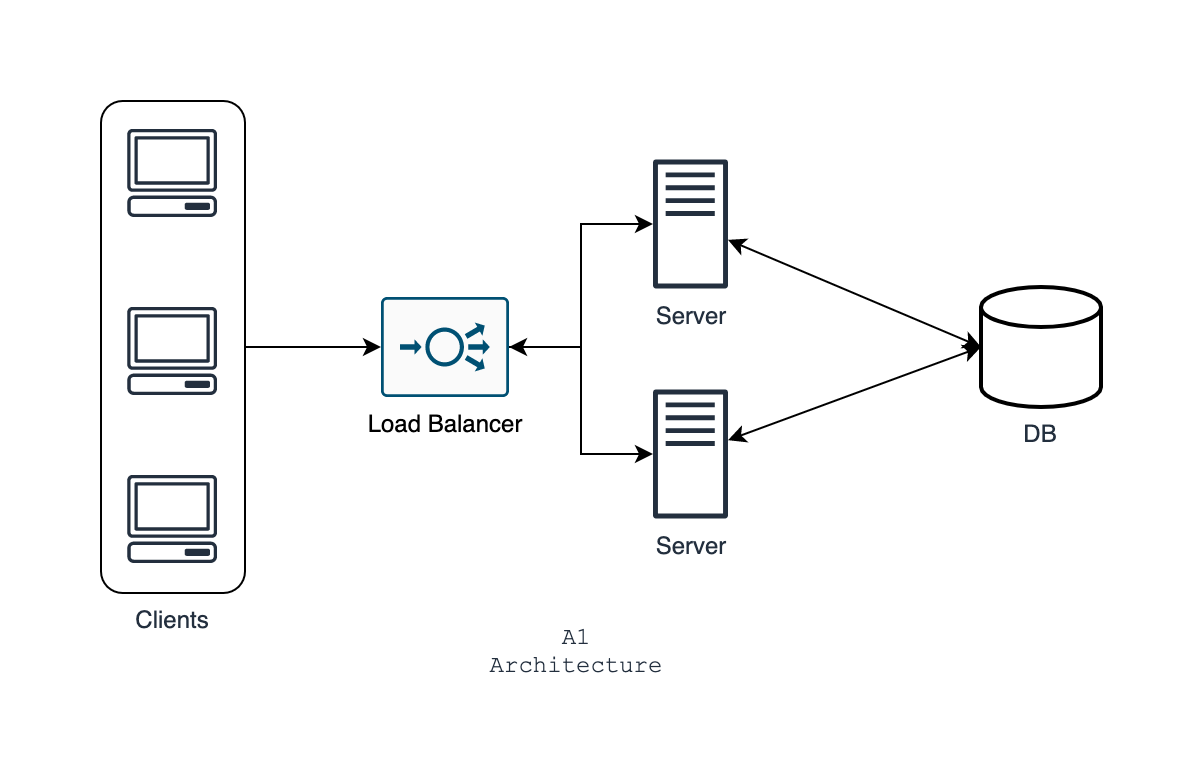
Let's name this architecture A1. After implementing this architecture, you see the latency has been reduced to 2-3 seconds, it seemed acceptable. So, you're good for now.
Case 3: Moderate user base
Circle is not your hobby project anymore. It has gained huge popularity and there is a sudden spike in your network traffic. You have the following metrics with the A1 architecture
| Concurrent Users | Requests/second | Latency (Actual) | Latency (Expected) |
| 20K | 12K | 10sec | <= 2sec |
Before jumping to improvements, please note that I have removed the total user count and will continue to do so from this point onwards. Total user count doesn't affect the scalability in any way. We have to look for the active users who are using the application concurrently because those users are actually putting the load in the servers, not the inactive users.
Let's get back to the metrics. Ten-second latency is beyond acceptable. You set your expectation that the latency should be less than or equal to 2 seconds at this point. What to do to achieve this? Just add more servers
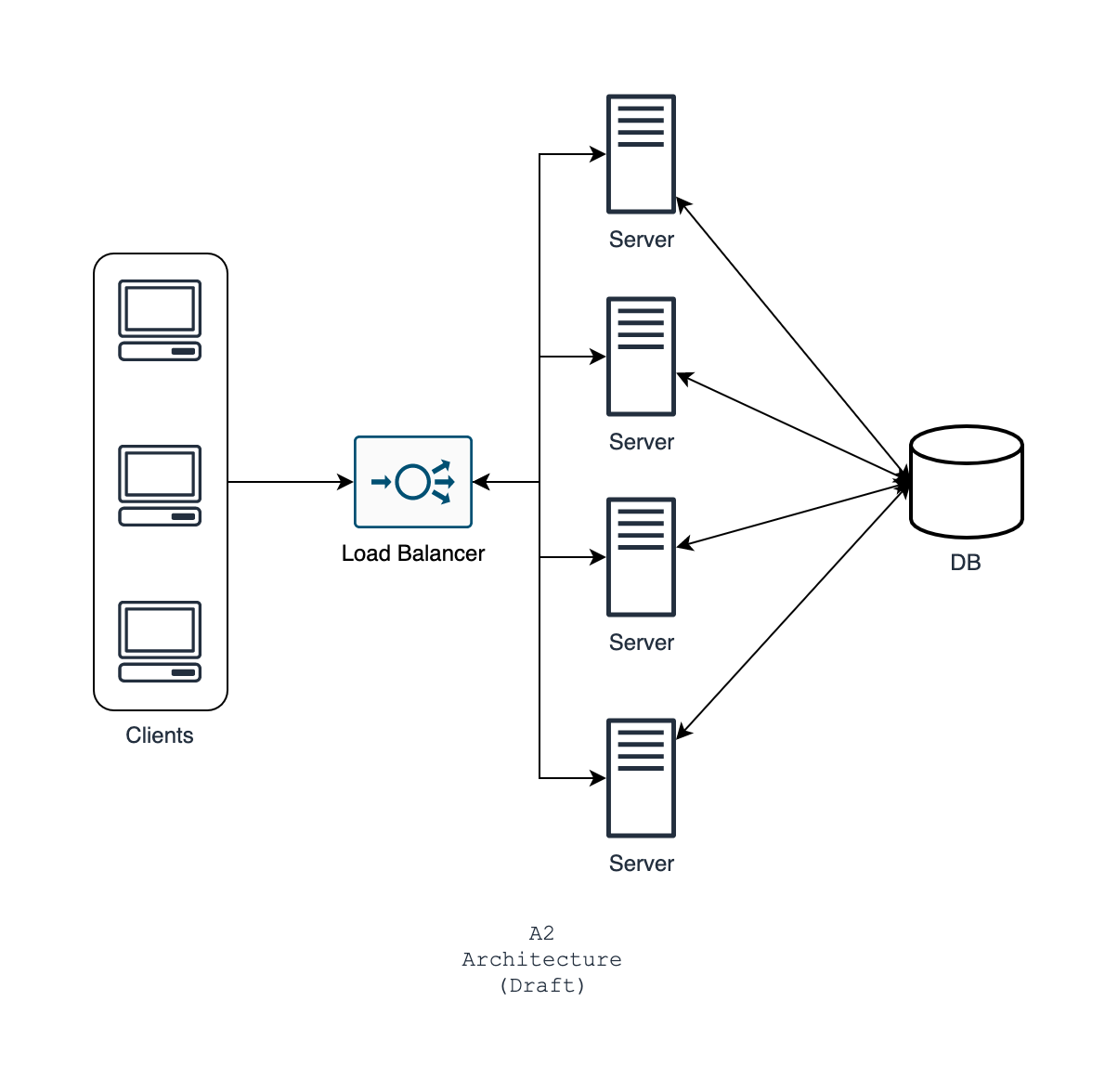
After implementing this, you see the latency has improved up to 4 seconds. But this is still below your expectation. Maybe you can do something else rather than adding more servers? Yes, you can. After some observation, you see that your database is facing a high load all the time.
Previously, we were only concentrating on servers because the server performance was the bottleneck. We just added more servers to overcome the issue. Now, the database load has become a performance bottleneck. If we don't address this database load, adding more servers will be of no use. Now, you may suggest adding more databases, just like we did with servers. But that is not preferable at this point for the given reasons:
- Databases are very expensive. A very simple managed database having only 30GB storage would cost you around 30-40$/month
- Syncing across databases and keeping data consistent across them is a very challenging task from an engineering perspective
Besides, databases are designed to handle huge loads and we aren't even close to the saturation point for the given scenario.
So, you monitor your weblogs and see that your application is read-heavy. It's a social platform, so people will actually read much more frequently than posting something in their timeline. This is true in many cases, most of the general applications are read-heavy.
Fortunately, there is an efficient way to reduce database load on reading operations. You just have to introduce a caching layer.
Caching: What caching basically does is that it stores frequently requested data in the memory (RAM). We know that RAM access is much faster. So if the data is found in caching layer, then there is no need to hit the database. Caching is done in memory, so it's much faster than a traditional database. If the data is not found in the cache, only then the request will be directed to the database. This mechanism will drastically reduce database load and significantly decrease read operation latency. For our social platform, frequently accessed data might be the user feeds, the reactions and comments, friend lists etc which can be easily cached. We can use Redis as the caching database.
On another note, caching is a very difficult thing to implement correctly. If the data changes, the cache needs to be updated. Otherwise, users will be served with old data. Besides, it's difficult to determine which data properties should be cached to achieve better results.
Now with the caching layer, you see that the latency is around 1-2 seconds. The final architecture for this case is given below
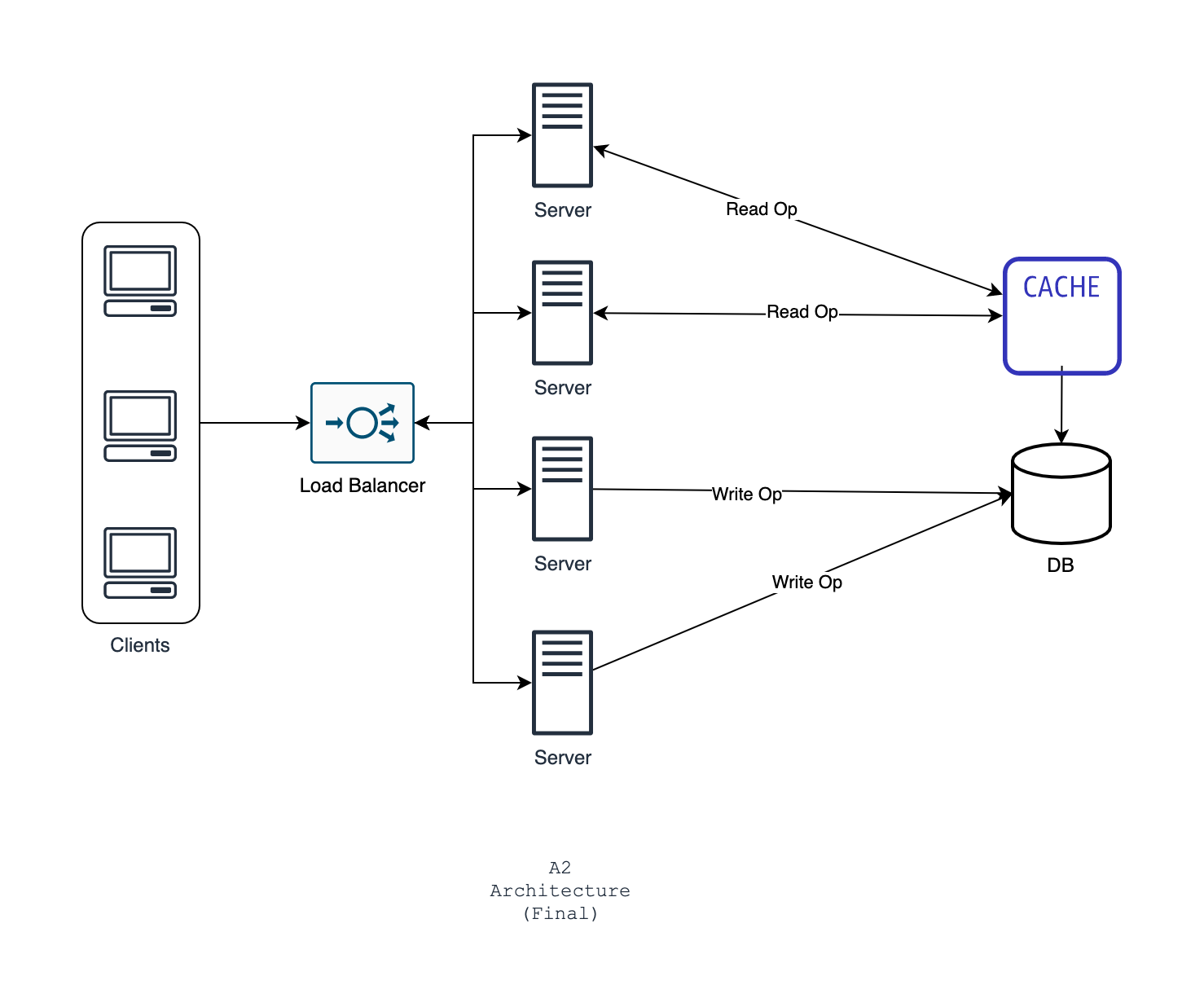
Let's name this architecture A2.
Evaluating your service reliability
One day, your service goes down for hours, your customers are angry and your platform will start losing profit. Your website is not reliable because it is down for hours. In a real-world scenario, just imagine the impact of Google being down for hours or Amazon.
So, how this downtime might occur? Well, the software is unpredictable. There might be downtime due to server maintenance issues, a bug that caused the server to crash etc. In the final architecture A2, can you imagine any possible scenario when the clients might not be able to connect to your platform, at all?
Let's say one of the servers from the server pool goes down due to some crash, there are still many other servers to handle the clients. The load balancer is intelligent enough to re-route new requests to the working servers. In the meantime, you can fix the issue with the bad server and once is fixed, it will be back in the working pool again. So, the server downtime issue is already fixed. Can you imagine any other devastating scenario? Is there any fault with the current architecture?
Understanding "Single Point of Failure"
Previously, if one server went down, the load balancer would re-route the request to other working servers. The load balancer itself is a server. What happens if the load balancer goes down? If you look into the architecture carefully, load balancer was the single point where all your clients connected. The clients only know the load balancer IP, the server IPs are never exposed to the clients. Such points are called single point of failures, as if that point stops working, your whole system is down. In a system architecture, we often have to look out and eliminate such single failure points.
To solve this issue, just like the server, you have to add redundancy in load balancing too
There are multiple load balancers now, how the client would know which load balancer to connect?
Every service has a record in the DNS system. So, let's say if your DNS name is circle.com, then you can assign multiple IP addresses for the same DNS. As you have guessed, the IP addresses will be the load balancer IPs. So, the DNS will be responsible for distributing the requests. Now, you might ask, what would happen if the DNS is down? Practically, if DNS is down, the whole internet is down. DNS is a global thing and I don't know any incidences of the DNS system being down. The architecture is given below:
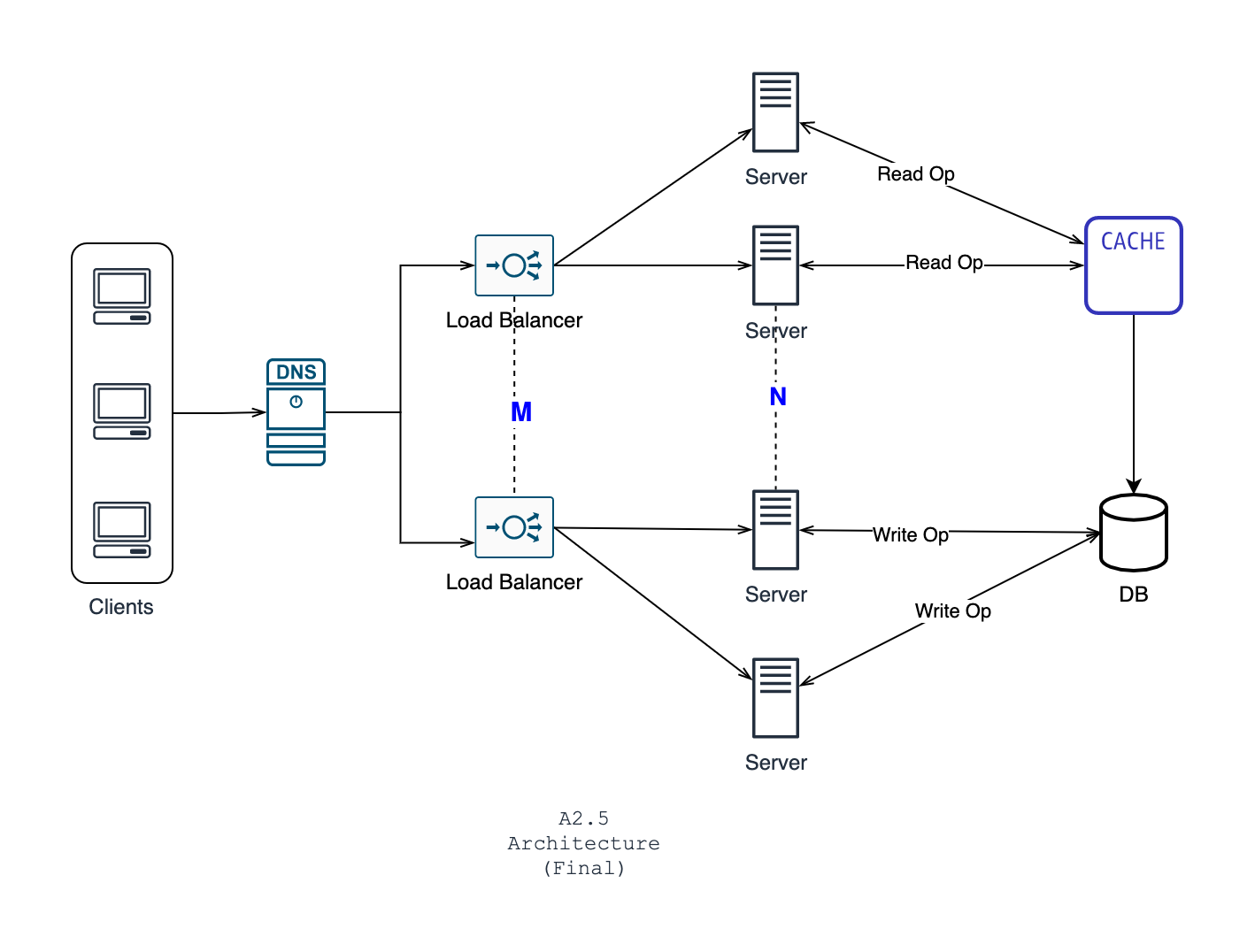
Here, we have placed M number of load balancers and N number of servers, where M << N. Let's name it A2.5. This architecture has no single point of failures.
What about database failures?
Currently, we have a traditional database and a caching database in the system. This might also go down. But, we assume that we are using managed databases. It means the providers of the database (like AWS, Google Cloud) will manage the database for us. Providers will constantly keep a backup and redundancies as required.
Case 4: Large user base
With the previous A2.5 architecture, you can serve a large number of users just by increasing values of M (load balancer count) and N (server count). But at one point, there is a very high chance that you will face a performance bottleneck in the database. It's simple, more users, more data. And even databases can get slow if you try to run queries in, let's say 500M data rows. It might seem like a lot of data, but this is common for very large applications.
Let's go through our current observations, where we assume that the values of M and N is high enough for a large system:
| Concurrent Users | Requests/second | Latency (Actual) | Latency (Expected) |
| 100K | 80K | 6s | <= 2sec |
So, this is the time to introduce some complexity in the data layer by introducing a master-slave architecture.
In a real-life scenario, you will have a lot more options before making your data layer complex. For example, breaking down services and scaling up separate services as required, each having their own database systems. But for the sake of learning and simplicity, we are considering a mono repo (single-service) with a single database
Master-slave architecture for the data layer
In such an architecture, there are multiple nodes of the same type. There is only one master node who are tasked with an important responsibility, whereas the slaves are helping hands for the master.
If we apply this architecture to a database system, you will have multiple databases. Among them, one will be master and the others will be slaves. One common practice is given below:
- Read operations will be handled by slaves
- The master will handle ONLY the write operations
- There will be a synchronization service to propagate the write changes from master to slaves
Let's see how our final architecture would look like with the master-slave database in place:
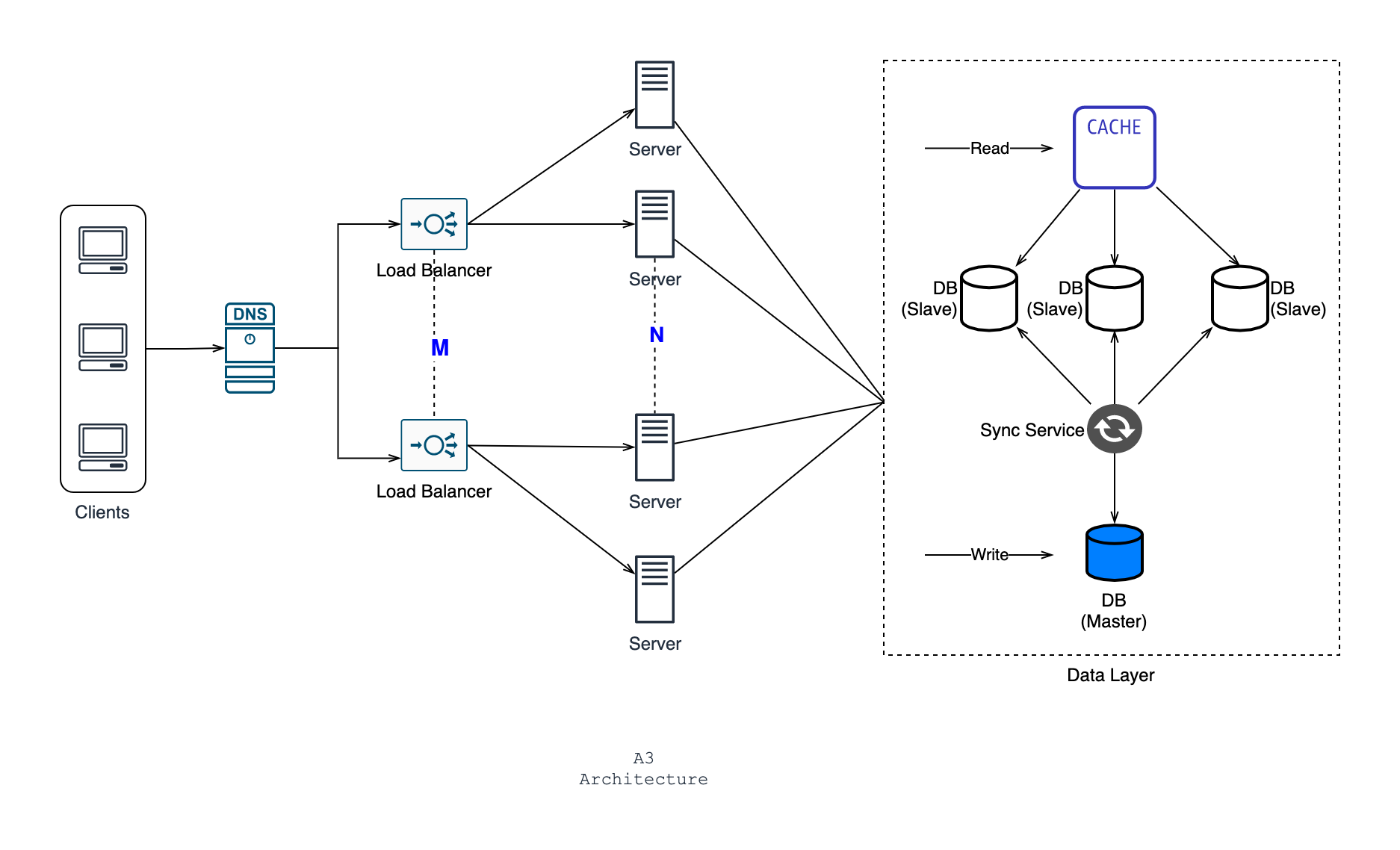
After implementing this, you see your latency is reduced to 2s. So you're satisfied for now. Please note, this architecture is not perfect for practical use cases. To keep things simple I have removed several redundancies and components. Let's name it A3 for future references.
Case 5: Huge user base
Your users have expanded through different geographical regions. Your new metrics are:
| Concurrent Users | Requests/second | Latency (Actual) | Latency (Expected) |
| 500K | 300K | 5s | <= 2sec |
And you have the following observations:
- Your servers are situated in Asia (assume). Your USA user base is having high latency because of the extra distance the network packets have to travel
- The data storage is so so huge that it seems it is not possible to store all the data in the master database
Now, solving this is very complicated and obviously too advanced for a beginner. Besides, there is no "correct" system design. But you have come this far, so I will give you a very high-level idea of how such scaling can be achieved:
- Each region (Asia/Europe) will have its own independent architecture
- There will be a gateway service for each architecture. When different regions need to talk to each other, they will use the gateway. The gateway service will decide what to do.
- There will be a huge sized main data centre that will collect all data from different regions and will serve as the single source of truth. It will have its own redundancies.
The simplest presentation of the architecture is given below:
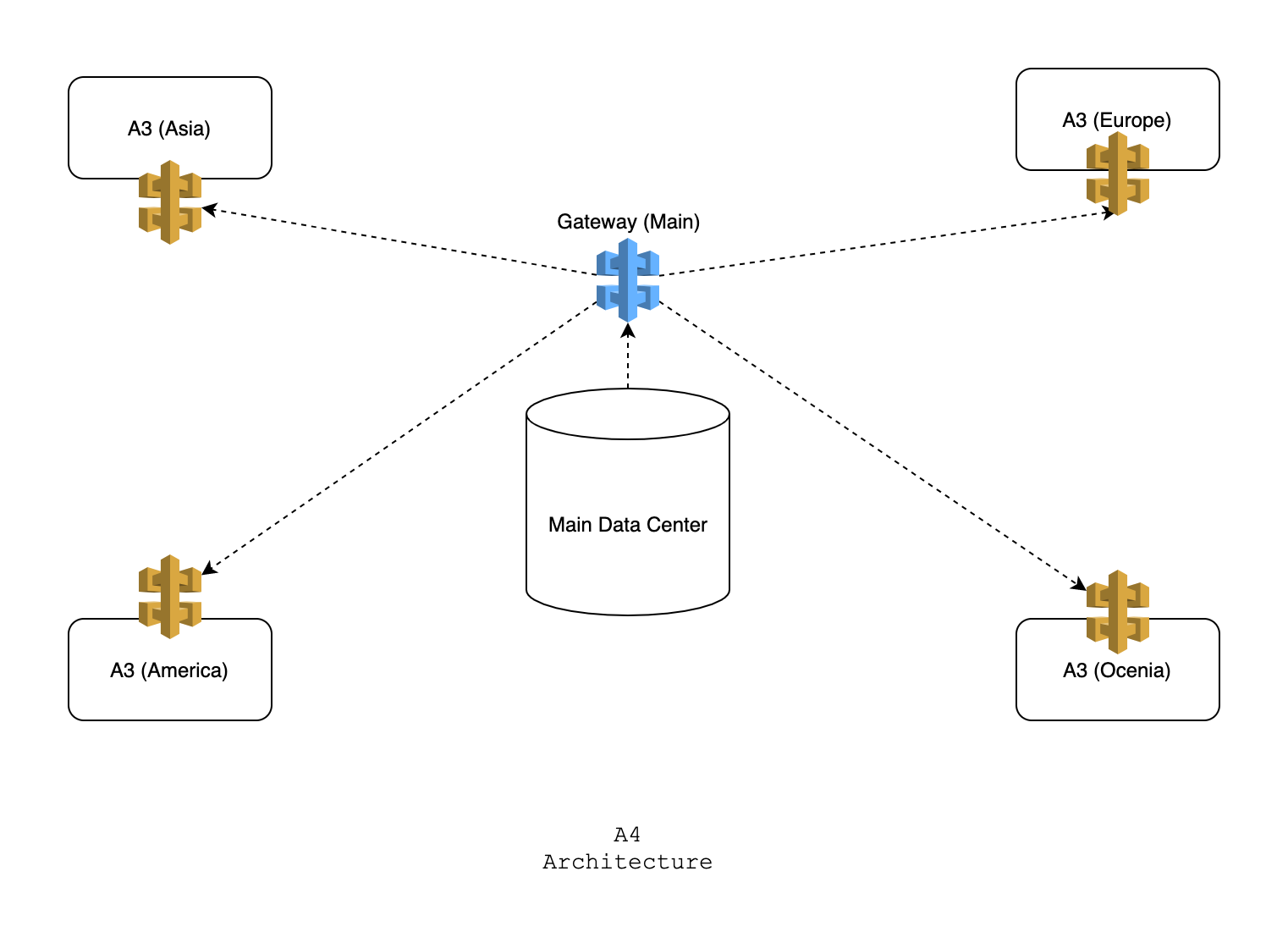
This is as far as I can go in terms of complexity. This is more than enough for a new learner. I wish I could have said to you that at this point, you know many things about system architecture. But to be honest, I can't say that. System architecture is much more complicated than what is shown here. We just scratched the surface. For example, we considered only client, server and databases. But in a real-world large scale application, there might be hundreds of different components working together. Interesting, isn't it?
I hope you have learnt something valuable and enjoyed reading this article. Please leave your feedback and questions in the comments below. If you like my articles, don't forget to follow and subscribe. Thank you!




