Multiprocessing, Multithreading and GIL: Essential concepts for every Python developer

Software Engineer | Mentor | Cats | Food | Loves to learn
Multithreading and Multiprocessing are ways to utilize 100% of the CPU and create performant applications. If you work with complex web applications, machine learning models or video/image editing tools then you have to tackle multithreading/multiprocessing sooner or later.
Let's say you create an application for editing photos. When the photo has a very high resolution, you will see a very significant drop in performance. Why? Because image editing is mathematically expensive. It puts pressure on the processor. To improve performance, you have to introduce multiprocessing/multithreading. In that case, if a user's CPU has 4 cores, your application should use all 4 cores if required.
Compared to other languages, multiprocessing and multithreading have some limitations in Python. Lacking the knowledge might result in creating slow and inefficient systems. The main purpose of this article is to understand the difference.
Let's get started by knowing a little bit more about Multithreading and Multiprocessing
Multithreading vs Multiprocessing
Let's see the basic differences first
Multithreading
- A single process, having multiple code segments that can be run concurrently
- Each code segment is called a thread. A process having multiple threads is called a multi-threaded process
- The process memory is shared among the threads. So thread A can access the variables declared by thread B
- Gives the impression of parallel execution, but it's actually concurrency which is not the same as parallelism. Although, threads can run in parallel in a multi-core environment (more on this later)
- Threads are easier to create and easier to throw away
Multiprocessing
- Multiple processes, working independently of each other. Each process might have one or more threads. But a single thread is the default.
- Each process has its own memory space. So process A cannot access the memory of process B
- Two different processes can run at two different cores in parallel independent of each other
- There is a significant overhead of creating and throwing away processes
Now, the terms concurrency and parallelism are not the same. By concurrent execution it means a task can start, progress and complete in overlapping time. It doesn't necessarily mean that they are running at the same instant. On the other hand, parallel execution means two tasks are literally running at the same instant (in a multi-core environment).
Also, we have to understand the difference between I/O bound and CPU bound operations.
If an operation depends on I/O (input/output) devices to complete its work, then it's I/O bound operation. For example, network requests, reading from a database or hard disk, reading from memory, writing to database - all these are I/O bound.
If an operation depends on the processor to complete its work, then it's a CPU bound operation. For example, matrix multiplication, sorting arrays, editing images, video encoding/decoding, training ML models all are CPU bound operations. The common thing here is a mathematical operation. Every example stated here involves heavy mathematical calculation which can be done by the processor only.
In a single-core processor, thread execution might look like below
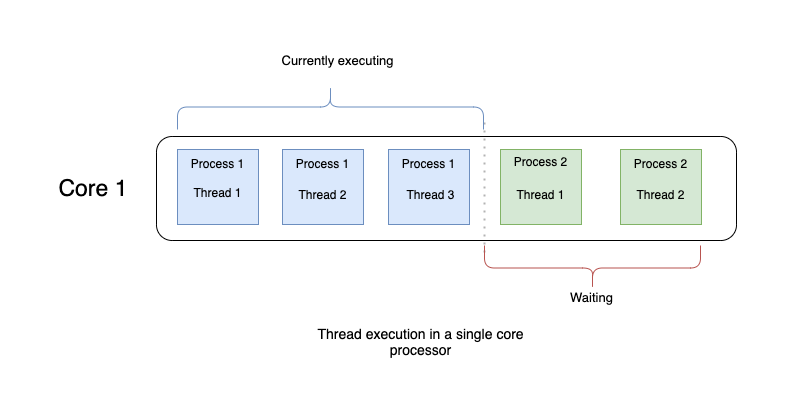
There are two processes, namely Process 1 and Process 2. While Process 1 is executing, Process 2 has to wait. In the case of threads, they can be executed concurrently (not in parallel). So for example, if Thread 1 issues a web request, it can take some time for the web request to complete. In that idle time, the CPU will be given to Thread 2 and it can do its operation (maybe do another web request). Please note, thread switching is efficient if it's an I/O bound operation. In the case of CPU bound operation, it doesn't yield better results from the performance perspective.
In a multi-core scenario, thread execution might look like this:
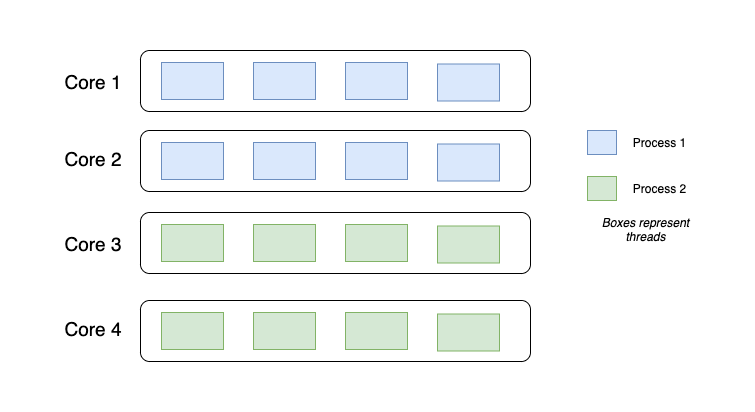
In the above figure, there are 2 processes each having 8 threads (16 threads in total). As you can see, threads for Process 1 have expanded to core 2. Threads 1-4 and threads 5-8 (blue boxes, top to bottom) are executed in parallel, because they are running in different cores. The same applies to Process 2. Concurrency among the threads in a single core is still preserved. Thus, the computation power is doubled for a process. This was possible when we used multithreading in a multi-core environment.
Now, when to use multithreading and when to use multiprocessing? It depends. Based on the characteristics described above, a programmer will go with either of them. If communication is important, then threads might be better because memory is shared. There are some more factors involved but to keep things simple, we will not dive into those. But in the case of performance, there is a very subtle difference. Creating more processes would be slower than creating threads because processes have an extra overhead and threads are more lightweight in nature.
In most cases, a C++ or Java programmer will go with multithreading unless there is an absolute need to go with multiprocessing (btw, don't mix up the term multiprocessing and multi-core). But, can we say the same thing for Python? Unfortunately, no. Python is different from C++ or Java.
What's so different in Python?
Previously, we saw that threads of the same process might expand to the second core or more if required. Unlike C++ or Java, Python's multithreading cannot expand to the second core by default no matter how many threads you create or how many cores the computer might have. All the threads will be run in a single core. Why? It's to make the program thread-safe.
We know that memory space is shared between threads. So let's say you have a variable named counter which has a value of 3, counter = 3. Now, if thread A is modifying the counter variable, thread B should wait for thread A to complete. If both of them tries to modify the variable at the same time, there will be a race condition and the final value will be inconsistent. So, there should be some locking mechanism which can prevent the race condition.
Java and C++ use some other kind of locking mechanism to prevent the race condition. Python uses GIL.
Introducing Global Interpreter Lock (GIL)
We know that Python is an interpreted language and thus it runs in an interpreter. GlL is a type of mutex lock that locks the interpreter itself.
Python uses reference counting for memory management. It means that objects created in Python have a reference count variable that keeps track of the number of references that point to the object. When this count reaches zero, the memory occupied by the object is released. Let's see an example to make it more clear
import sys
a = 'Hello World'
b = a
c = a
sys.getrefcount(a) # outputs 4
For the above example, the variable a is referenced in 4 places. The variable was referenced during the statements a = 'Hello World', b = a, c = a and sys.getrefcount(a).
Now, this reference counting system needs protection from a race condition. Otherwise, threads may try to increase or decrease the reference values simultaneously. If this happens then it would cause memory leaks, or, incorrectly release memory when the object/variable is still in use. This is where GIL comes into play. It's a single lock on the interpreter itself. It enforces the rule that any Python bytecode must acquire the interpreter lock before it can be executed.
Alternative Python Interpreters: One thing to note, GIL is only used in the CPython implementation of the Python language. CPython is written in C. This is the official and most popular implementation that you download from the Python website. Just so you know, there are other interpreter implementations of Python, such as Jython (written in Java), IronPython (written in C#) and PyPy (written in Python). These implementations don't have GIL. Although, they are not popular and very few libraries support them. Also, in later portions, you will know although seemingly obstructive, why GIL was chosen as the best solution.
The impact of GIL in multithreaded Python program
As GIL locks the interpreter itself, parallel execution of the program is not possible for a single process. So even if you create one hundred threads, all of them will run in a single core because of the GIL. The following figure clarifies how it would look
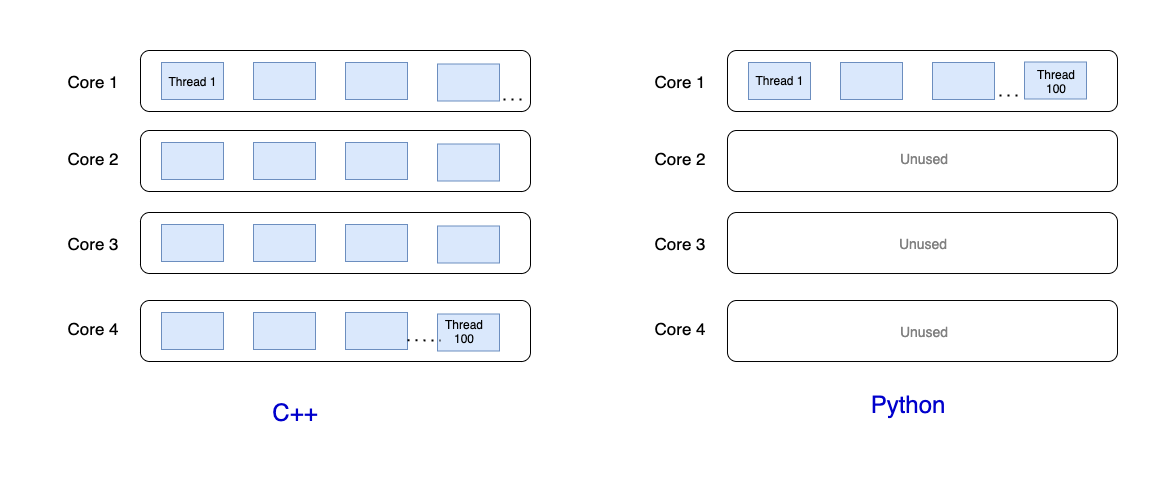
For C++, a hundred threads have been distributed in four cores. For Python, all the one hundred threads are running under the same core because of GIL.
The Remedy
It is possible to run a Python program utilizing all the cores available to you. How? Using multiprocessing instead of multithreading. For the record, I will show how to easily create a thread pool and process pool in Python. Of course, there are other ways to create threads and processes. But the one I'm going to show is more than enough in most cases.
In Python, when to use multithreading and when to use multiprocessing?
If your program does I/O heavy tasks, go for multithreading. Doing multiprocessing here would be a bad idea because of extra overhead. On the other hand, if your program does mathematical calculations, go with multiprocessing. Using thread, in this case, might result in decreased performance. If your program does both I/O and CPU related tasks, then you have to use a hybrid of both.
Multithreading with ThreadPoolExecutor
Let's say you have a program that scrapes web pages. Web requests are I/O bound operation, so threads are perfect here. Look at the code below:
from concurrent.futures import ThreadPoolExecutor, wait
def scrape_page(url):
# ... scraping logic
# remove the following line when you have written the logic
raise NotImplementedError
def batch_scrape(urls):
tasks = []
with ThreadPoolExecutor(max_workers=8) as executor:
for url in urls:
# for executor.submit, the first argument will be the name of the function to execute. All the argument after that will be passed as the executing function's argument
tasks.append(executor.submit(scrape_page, url))
wait(tasks)
if __name__ == "__main__":
urls = ['https://google.com', 'htpps://facebook.com']
batch_scrape(urls)
In the given code example, 8 threads will be spawned. We mentioned it using the max_workers argument.
Multiprocessing with ProcessPoolExecutor
Fortunately, ThreadPoolExecutor and ProcessPoolExecutor uses the same interface. So, the code will be almost similar to the previous one. For this example, we will assume we're encoding video files, which is a CPU intensive task
from concurrent.futures import ProcessPoolExecutor, wait
def encode_video(file):
# ... encoding logic
# remove the following line when you have written the logic
raise NotImplementedError
def batch_encode(files):
tasks = []
with ProcessPoolExecutor(max_workers=4) as executor:
for file in files:
tasks.append(executor.submit(encode_video, file))
wait(tasks)
if __name__ == "__main__":
filePaths = ['file1.mp4', 'file2.mp4']
batch_encode(filePaths)
Here, 4 processes will be created. All four process can run in parallel because each process has its own interpreter. Thus, the GIL limitation doesn't matter in this case.
Why GIL?
Now that you know how to run your Python program utilizing multiple cores, you might wonder why use GIL instead of other solutions. Also, why not remove GIL?
Python is a very popular and widely used language. With many good sides, there are some bad sides like GIL (or, is it really a bad side? let's see). If it was not for GIL, Python would not be so popular nowadays. Let's see the reasons
Other languages like Java/C++ use different locking mechanisms but with the cost of decreased performance for single-threaded programs. To overcome single-threaded performance issue they use something like JIT compilers
If you try to add multiple locks, there might be a deadlock situation. Also constantly releasing and acquiring locks has performance bottlenecks. It's not very easy to overcome these things while keeping awesome language features. GIL is a single lock and simple to implement.
Python is popular and widely used because of its underlying support for C extension libraries. C libraries needed a thread-safe solution. GIL is a single lock on the interpreter, so there is no chance of deadlocks. Also, it's simpler to implement and maintain. So ultimately GIL was chosen to support all those C extensions
Developers and researchers tried to remove GIL in the past. But as a result, they saw a significant performance drop for single-threaded applications. You should note that most general applications are single-threaded. Also, the underlying C libraries on which Python heavily depends got completely broken. A major thing like GIL cannot be removed without causing backward compatibility issues or slowing down performance. But still, researchers are trying to get rid of GIL and it's a topic of interest for many.
Ultimately, it seemed that the GIL limitations are not causing any impact when it comes to writing large and complex applications. After all, multiprocessing is still there to solve such problems. Today's modern computers have enough resource and memory to tackle multiprocessing related overheads.
That's it for today. I hope you learnt something new and interesting. If you like my article, please follow and subscribe to my blog . Also, if you have any questions or feedback, drop a comment below. Thank you.




